Auto-claude-code-research-in-sleep (ARIS ⚔️)
中文版 README | English

🌙 Let Claude Code do research while you sleep. Wake up to find your paper scored, weaknesses identified, experiments run, and narrative rewritten — autonomously.
Custom Claude Code skills for autonomous ML research workflows. These skills orchestrate cross-model collaboration — Claude Code drives the research while an external LLM (via Codex MCP) acts as a critical reviewer. 🔀 Also supports alternative model combinations (e.g., GLM + GPT, GLM + MiniMax) — no Claude API required.
💭 Why not self-play with a single model? Using Claude Code subagents or agent teams for both execution and review is technically possible, but tends to fall into local minima — the same model reviewing its own patterns creates blind spots. Claude Code's strength is fast, fluid execution; Codex (GPT-5.4 xhigh) is slower but more deliberate and rigorous in critique. These complementary styles — speed × rigor — produce better outcomes than either model talking to itself.
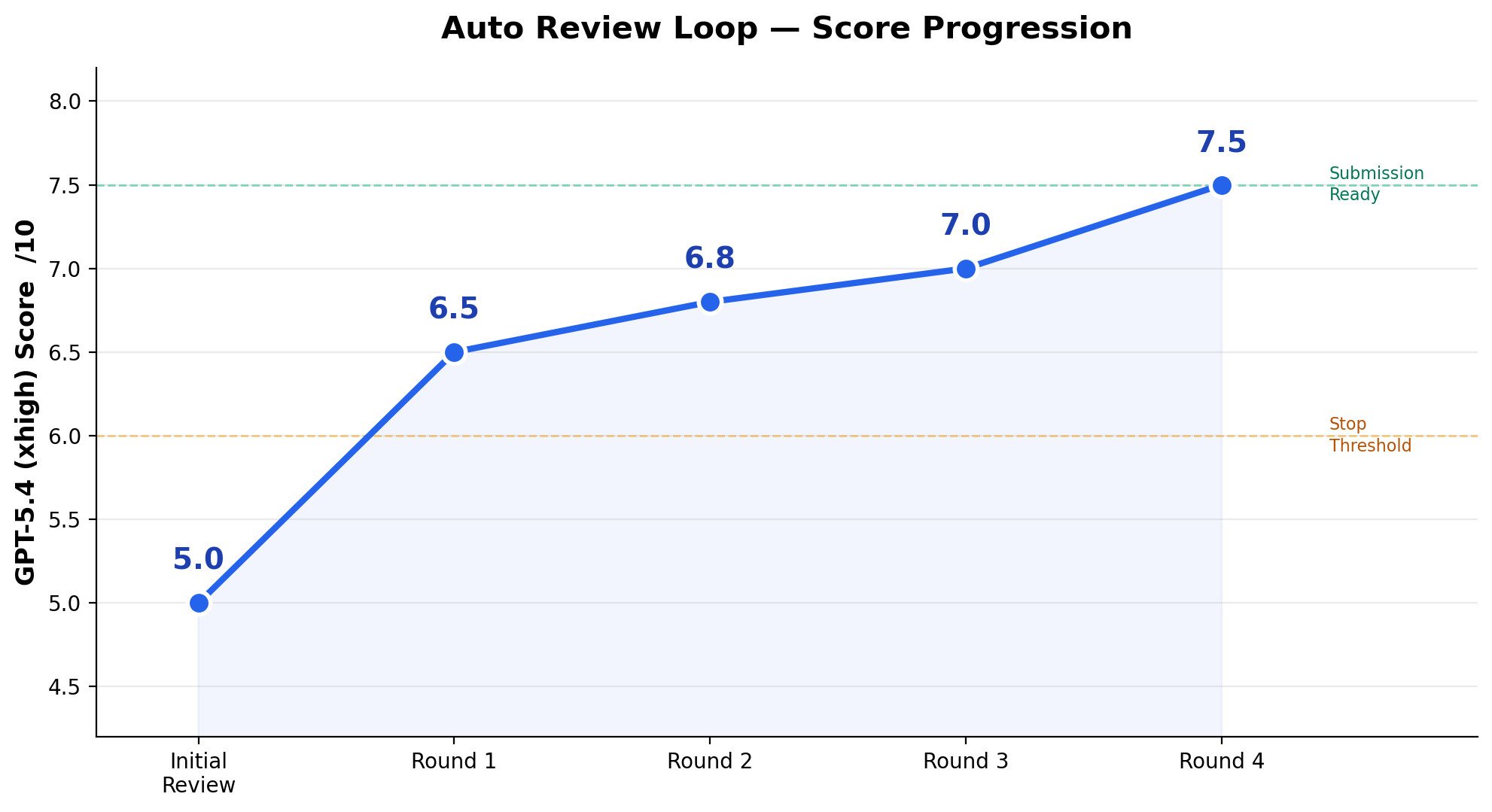
📈 Score Progression (Real Run)
A real overnight 4-round run on an ML research project, from borderline reject to submission-ready:
| Round | Score | What Happened |
|---|---|---|
| Initial | 5.0/10 | Borderline reject |
| Round 1 | 6.5/10 | Added standard metrics, discovered metric decoupling |
| Round 2 | 6.8/10 | Key claim failed to reproduce, pivoted narrative |
| Round 3 | 7.0/10 | Large seed study killed main improvement claim |
| Round 4 | 7.5/10 ✅ | Diagnostic evidence solidified, submission ready |
The loop autonomously ran 20+ GPU experiments, rewrote the paper's narrative framing, and killed claims that didn't hold up — all without human intervention.
💡 Idea Discovery (New)
Don't have a concrete idea yet? Just give a research direction — /idea-creator handles the rest:
- 📚 Survey the landscape (recent papers, open problems, recurring limitations)
- 🧠 Brainstorm 8-12 concrete ideas via GPT-5.4 xhigh
- 🔍 Filter by feasibility, compute cost, and quick novelty search
- 🛡️ Validate top ideas with deep novelty check + devil's advocate review
- 🧪 Pilot top 2-3 ideas in parallel on different GPUs (30 min - 2 hr each)
- 🏆 Rank by empirical signal — ideas with positive pilot results rise to the top
The output is a ranked IDEA_REPORT.md with hypotheses, pilot results, reviewer objections, and a suggested execution order. Ideas that fail are documented too, saving future dead-end exploration.
🔄 Workflows
These skills compose into a full research lifecycle. The two workflows can be used independently or chained together:
- Exploring a new area (e.g., writing a survey)? Start with Workflow 1 →
/idea-discovery - Already have an idea + initial plan? Jump straight to Workflow 2 →
/auto-review-loop - Full pipeline? Workflow 1 → Workflow 2 →
/research-pipeline— from literature survey all the way to submission
⚠️ Important: These tools accelerate research, but they don't replace your own critical thinking. Always review generated ideas with your domain expertise, question the assumptions, and make the final call yourself. The best research comes from human insight + AI execution, not full autopilot.
Full Pipeline 🚀
/research-lit → /idea-creator → /novelty-check → implement → /run-experiment → /auto-review-loop → submit
(survey) (brainstorm) (verify novel) (code) (deploy & run) (review & fix) (done!)
├──── Workflow 1: Idea Discovery ────┤ ├──────── Workflow 2: Auto Loop ────────┤
📝 Blog post: 梦中科研全流程开源
Workflow 1: Literature & Idea Discovery 🔍
"What's the state of the art? Where are the gaps?"
┌─────────────────────────────────────────────────────────────┐
│ Idea Discovery │
│ │
│ /research-lit /idea-creator /novelty-check │
│ (find papers) (brainstorm) (verify novelty) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Scan │────▶│ Generate │──────▶│ Check if │ │
│ │ local │ │ 8-12 │ │ idea is │ │
│ │ papers + │ │ ideas │ │ novel │ │
│ │ search │ │ + rank │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Filter │──────▶│ External │ │
│ │ by cost, │ │ LLM │ │
│ │ novelty │ │ evaluates│ │
│ └──────────┘ └──────────┘ │
│ │
│ Typical flow: │
│ 1. /research-lit "discrete diffusion models" (local → online) │
│ 2. /idea-creator "DLLMs post training" │
│ 3. Review ranked ideas, pick top 2-3 │
│ 4. /novelty-check "top idea" (deep verification) │
│ 5. /research-review "top idea" (critical feedback) │
│ 6. Implement → /run-experiment → /auto-review-loop │
└─────────────────────────────────────────────────────────────┘
Skills involved: research-lit + idea-creator + novelty-check + research-review
💡 One-command shortcut:
/idea-discovery "your research direction"runs this entire workflow automatically.
🔄 Human-in-the-loop: Each phase presents results and waits for your feedback. Not happy? Tell it what's missing — it refines the prompt and regenerates. Trust the defaults? It auto-proceeds with the top-ranked option. You decide how hands-on to be.
⚙️ Pilot experiment budgets (max hours, timeout, GPU budget) are configurable — see Customization.
📝 Blog post: Claude Code 两月 NeurIPS 指北
Workflow 2: Auto Research Loop 🔁 (sleep & wake up to results)
"Review my paper, fix what's wrong, repeat until it's good."
┌─────────────────────────────────────────────────────────────┐
│ Auto Review Loop │
│ │
│ /research-review /auto-review-loop │
│ (single deep review) (autonomous loop) │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ External │──▶│ Implement│──▶│ Monitor │──▶ repeat │
│ │ LLM │ │ fixes │ │ results │ until │
│ │ reviews │ │ & run │ │ │ score ≥ 6 │
│ └──────────┘ │ experiments│ └──────────┘ │
│ └──────────┘ │
│ │
│ When reviewer suggests a new method direction: │
│ /novelty-check — verify idea isn't already published │
│ │
│ Supporting skills: │
│ /run-experiment — deploy to local/remote GPU │
│ /analyze-results — interpret experiment outputs │
│ /monitor-experiment — check progress, collect results │
└─────────────────────────────────────────────────────────────┘
Skills involved: auto-review-loop + research-review + novelty-check + run-experiment + analyze-results + monitor-experiment
💡 One-command shortcut:
/auto-review-loop "your paper topic"runs this entire workflow automatically.
🛡️ Key safety features:
- 🔒 MAX_ROUNDS = 4 — prevents infinite loops; stops early if score threshold is met
- ⏱️ > 4 GPU-hour experiments skipped — won't launch massive jobs; flags them for manual follow-up
- 🧠 Prefer reframing over new experiments — when both can address a weakness, chooses the cheaper path
- 🪞 No hiding weaknesses — explicit rule: "Do NOT hide weaknesses to game a positive score"
- 🔧 Fix before re-review — must actually implement fixes before resubmitting; no empty promises
⚙️ MAX_ROUNDS, score threshold, and GPU limits are configurable — see Customization.
📝 Blog post: 开源 | 睡觉 Claude 自动跑实验改文
🧰 All Skills
| Skill | Description | Needs Codex MCP? |
|---|---|---|
💡 idea-creator | Generate and rank research ideas given a broad direction (brainstorm + filter + validate) | Yes |
🔬 research-review | Single-round deep review from external LLM (xhigh reasoning) | Yes |
🔁 auto-review-loop | Autonomous multi-round review→fix→re-review loop (max 4 rounds) | Yes |
📚 research-lit | Scan local paper library + search online, analyze related work, find gaps | No |
📊 analyze-results | Analyze experiment results, compute statistics, generate insights | No |
👀 monitor-experiment | Monitor running experiments, check progress, collect results | No |
🔍 novelty-check | Verify research idea novelty against recent literature before implementing | Yes |
🚀 run-experiment | Deploy experiments to local (MPS/CUDA) or remote GPU servers | No |
🎨 pixel-art | Generate pixel art SVG illustrations for READMEs, docs, or slides | No |
🔭 idea-discovery | Workflow 1 pipeline: research-lit → idea-creator → novelty-check → research-review | Yes |
🏗️ research-pipeline | Full pipeline: Workflow 1 → implement → Workflow 2, from direction to submission | Yes |
⚙️ Setup
Prerequisites
- Claude Code installed
- (For review skills) Codex CLI installed and configured as MCP server:
npm install -g @openai/codex claude mcp add codex -s user -- codex mcp-server
Install Skills
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
# Install all skills globally
cp -r skills/* ~/.claude/skills/
# Or install specific skills
cp -r skills/auto-review-loop ~/.claude/skills/
cp -r skills/research-lit ~/.claude/skills/
Usage
> /idea-creator DLLMs post training
> /research-lit discrete diffusion language models
> /research-review my paper on training dynamics in D-LLMs
> /auto-review-loop ML paper on factorized gap diagnosis
> /run-experiment train.py --lr 1e-4 --epochs 100
> /analyze-results figures/*.json
> /monitor-experiment server5
> /idea-discovery discrete diffusion language models
> /research-pipeline DLLMs post training
🌙 Auto-Allow for Overnight Runs (Optional)
To run the auto-review loop without clicking permission prompts, add to .claude/settings.local.json:
{
"permissions": {
"allow": [
"mcp__codex__codex",
"mcp__codex__codex-reply",
"Write",
"Edit",
"Skill(auto-review-loop)"
]
}
}
🖥️ GPU Server Setup (For Auto-Experiments)
When GPT-5.4 says "run an ablation study" or "add a baseline comparison", Claude Code automatically writes the experiment script and deploys it to your GPU server. For this to work, Claude Code needs to know your server environment.
Add your server info to your project's CLAUDE.md:
## Remote Server
- SSH: `ssh my-gpu-server` (key-based auth, no password)
- GPU: 4x A100
- Conda env: `research` (Python 3.10 + PyTorch)
- Activate: `eval "$(/opt/conda/bin/conda shell.bash hook)" && conda activate research`
- Code directory: `/home/user/experiments/`
- Use `screen` for background jobs: `screen -dmS exp0 bash -c '...'`
Claude Code reads this and knows how to SSH in, activate the environment, and launch experiments. GPT-5.4 (the reviewer) only decides what experiments to run — Claude Code figures out how based on your CLAUDE.md.
No server? The review and rewriting skills still work without GPU access. Only experiment-related fixes will be skipped (flagged for manual follow-up).
🏗️ How It Works
┌─────────────────────────────────────────────────┐
│ Claude Code │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Read │ │ Write │ │ SSH to │ │
│ │ project │───▶│ code & │───▶│ GPU │ │
│ │ context │ │ scripts │ │ server │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────┐ │
│ │ Codex MCP (External LLM) │ │
│ │ │ │
│ │ Round 1: "Score 5/10. Weaknesses: ..." │ │
│ │ Round 2: "Score 6.5. Better, but ..." │ │
│ │ Round 3: "Score 7.0. Almost there..." │ │
│ │ Round 4: "Score 7.5. Ready." ✅ │ │
│ └──────────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
The key insight: Claude Code handles execution (reading files, writing code, running experiments, collecting results) while the external LLM handles evaluation (scoring, identifying weaknesses, suggesting fixes). This separation creates a genuine feedback loop — neither model is grading its own work.
🎛️ Customization
Skills are plain Markdown files. Fork and customize:
Auto Review Loop (auto-review-loop)
| Constant | Default | Description |
|---|---|---|
MAX_ROUNDS | 4 | Maximum review→fix→re-review iterations |
POSITIVE_THRESHOLD | 6/10 | Score at which the loop stops (submission-ready) |
> 4 GPU-hour skip | 4h | Experiments exceeding this are flagged for manual follow-up |
Idea Discovery (idea-discovery / idea-creator)
| Constant | Default | Description |
|---|---|---|
PILOT_MAX_HOURS | 2h | Skip any pilot estimated to take longer per GPU |
PILOT_TIMEOUT_HOURS | 3h | Hard timeout — kill runaway pilots, collect partial results |
MAX_PILOT_IDEAS | 3 | Maximum number of ideas to pilot in parallel |
MAX_TOTAL_GPU_HOURS | 8h | Total GPU budget across all pilots |
AUTO_PROCEED | true | Auto-continue with top-ranked option if user doesn't respond. Set false to always wait for explicit approval |
Override inline: /idea-discovery "topic" — pilot budget: 4h per idea, wait for my approval at each step
Literature Search (research-lit)
| Constant | Default | Description |
|---|---|---|
PAPER_LIBRARY | papers/, literature/ | Local directories to scan for PDFs before searching online |
MAX_LOCAL_PAPERS | 20 | Max local PDFs to scan (first 3 pages each) |
Override inline: /research-lit "topic" — paper library: ~/Zotero/storage/
General (all skills using Codex MCP)
| Constant | Default | Description |
|---|---|---|
REVIEWER_MODEL | gpt-5.4 | OpenAI model used via Codex MCP. Options: gpt-5.4, o3, gpt-4o, etc. |
- Prompt templates — tailor the review persona and evaluation criteria
allowed-tools— restrict or expand what each skill can do
🔀 Alternative Model Combinations
Don't have Claude / OpenAI API access? You can swap in other models — same cross-model architecture, different providers.
| Role | Default | Alt A: GLM + GPT | Alt B: GLM + MiniMax |
|---|---|---|---|
| Executor (Claude Code) | Claude Opus/Sonnet | GLM-5 (ZhiPu API) | GLM-5 (ZhiPu API) |
| Reviewer (Codex MCP) | GPT-5.4 | GPT-5.4 (OpenAI API) | MiniMax-M2.5 (MiniMax API) |
| Need OpenAI API? | Yes | Yes | No |
Step 1: Install Claude Code & Codex CLI
npm install -g @anthropic-ai/claude-code
npm install -g @openai/codex
Step 2: Configure ~/.claude/settings.json
Open with: nano ~/.claude/settings.json
Alt A: GLM (executor) + GPT (reviewer) — Only replace Claude, keep GPT-5.4 as reviewer
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_zai_api_key",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5"
},
"mcpServers": {
"codex": {
"command": "/opt/homebrew/bin/codex",
"args": [
"mcp-server"
]
}
}
}
Codex CLI uses your existing OPENAI_API_KEY (from ~/.codex/config.toml or environment) — no extra config needed for the reviewer side.
Alt B: GLM (executor) + MiniMax (reviewer) — No Claude or OpenAI API needed
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_zai_api_key",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5",
"CODEX_API_KEY": "your_minimax_api_key",
"CODEX_API_BASE": "https://api.minimax.chat/v1/",
"CODEX_MODEL": "MiniMax-M2.5"
},
"mcpServers": {
"codex": {
"command": "/opt/homebrew/bin/codex",
"args": [
"mcp-server"
]
}
}
}
Save: Ctrl+O → Enter → Ctrl+X
Step 3: Install Skills & Run
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
cp -r skills/* ~/.claude/skills/
# Launch Claude Code (now powered by GLM)
claude
Step 4: Let GLM Read the Project ⚠️ IMPORTANT
🔴 Do NOT skip this step. GLM's prompt handling differs from Claude's. You must let GLM read through the project once to ensure skills are correctly parsed.
After launching claude, run in the conversation:
Read through this project and verify all skills are working:
/idea-creator, /research-review, /auto-review-loop, /novelty-check,
/idea-discovery, /research-pipeline, /research-lit, /run-experiment,
/analyze-results, /monitor-experiment, /pixel-art
For each skill, confirm: (1) it loads without errors, (2) the frontmatter is parsed correctly.
This lets GLM (acting as Claude Code) familiarize itself with the skill files and catch any compatibility issues upfront — rather than discovering them mid-workflow when it's expensive to fail.
⚠️ Note: Alternative models may behave differently from Claude and GPT-5.4. You may need to adjust
REVIEWER_MODELin the skills and tune prompt templates for best results. The core cross-model architecture remains the same.
📋 Roadmap
- Zotero MCP integration — read papers, tags, and annotations directly from Zotero library
- More executor × reviewer combinations (Gemini, DeepSeek, etc.)
💬 Community
Join the WeChat group for discussion on Claude Code + AI-driven research workflows:

⭐ Star History

License
MIT