![]()
FlowLLM: Simplifying LLM-based HTTP/MCP Service Development
If you find it useful, please give us a ⭐ Star. Your support drives our continuous improvement.

English | 简体中文
📖 Introduction
FlowLLM encapsulates LLM, Embedding, and vector_store capabilities as HTTP/MCP services. It is suitable for AI assistants, RAG applications, and workflow services, and can be integrated into MCP-compatible client tools.
🏗️ Architecture Overview
🌟 Applications Based on FlowLLM
| Project Name | Description |
|---|---|
| ReMe | Memory management toolkit for agents |
📢 Recent Updates
| Date | Update Content |
|---|---|
| 2025-11-15 | Added File Tool Op feature with 13 file operation tools, supporting file reading, writing, editing, searching, directory operations, system command execution, and task management |
| 2025-11-14 | Added Token counting capability, supporting accurate calculation of token counts for messages and tools via self.token_count() method, with support for multiple backends (base, openai, hf). See configuration examples in default.yaml |
📚 Learning Resources
Project developers will share their latest learning materials here.
| Date | Title | Description |
|---|---|---|
| 2025-11-24 | Mem-PAL: Memory-Augmented Personalized Assistant | Mem-PAL: Memory-Augmented Personalized Assistant with Log-based Structured Memory |
| 2025-11-14 | HaluMem Analysis | HaluMem: Evaluating Hallucinations in Memory Systems of Agents Analysis |
| 2025-11-13 | Gemini CLI Context Management Mechanism | Multi-layer Context Management Strategy for Gemini CLI |
| 2025-11-10 | Context Management Guide | Context Management Guide |
| 2025-11-10 | LangChain&Manus Video Materials | LangChain & Manus Context Management Video |
⭐ Core Features
-
Simple Op Development: Inherit from
BaseOporBaseAsyncOpand implement your business logic. FlowLLM provides lazy-initialized LLM, Embedding models, and vector stores accessible viaself.llm,self.embedding_model, andself.vector_store. It also offers prompt template management throughprompt_format()andget_prompt()methods. Additionally, FlowLLM includes built-in token counting capabilities. Useself.token_count()to accurately calculate token counts for messages and tools, supporting multiple backends (base, openai, hf, etc.). -
Flexible Flow Orchestration: Compose Ops into Flows via YAML configuration.
>>denotes serial composition;|denotes parallel composition. For example,SearchOp() >> (AnalyzeOp() | TranslateOp()) >> FormatOp()builds complex workflows. Define input/output schemas and start the service withflowllm config=your_config. -
Automatic Service Generation: FlowLLM automatically generates HTTP, MCP, and CMD services. The HTTP service provides RESTful APIs with synchronous JSON and HTTP Stream responses. The MCP service registers as Model Context Protocol tools for MCP-compatible clients. The CMD service executes a single Op in command-line mode for quick testing and debugging.
⚡ Quick Start
📦 Step0 Installation
📥 From PyPI
pip install flowllm
🔧 From Source
git clone https://github.com/flowllm-ai/flowllm.git
cd flowllm
pip install -e .
For detailed installation and configuration, refer to the Installation Guide.
⚙️ Configuration
Create a .env file and configure your API keys. Copy from example.env and modify:
cp example.env .env
Configure your API keys in the .env file:
FLOW_LLM_API_KEY=sk-xxxx
FLOW_LLM_BASE_URL=https://xxxx/v1
FLOW_EMBEDDING_API_KEY=sk-xxxx
FLOW_EMBEDDING_BASE_URL=https://xxxx/v1
For detailed configuration, refer to the Configuration Guide.
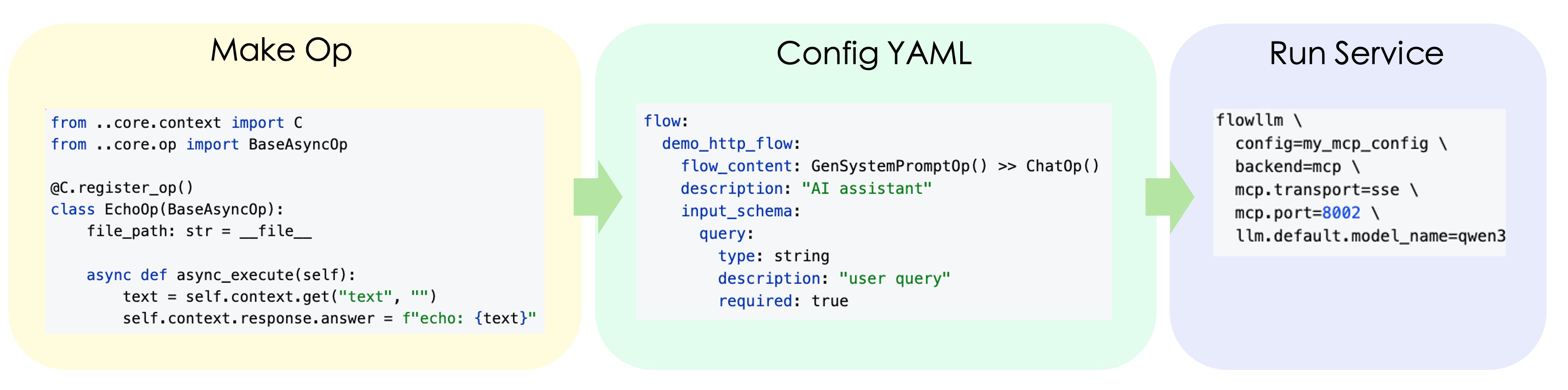
🛠️ Step1 Build Op
from flowllm.core.context import C
from flowllm.core.op import BaseAsyncOp
from flowllm.core.schema import Message
from flowllm.core.enumeration import Role
@C.register_op()
class SimpleChatOp(BaseAsyncOp):
async def async_execute(self):
query = self.context.get("query", "")
messages = [Message(role=Role.USER, content=query)]
# Use token_count method to calculate token count
token_num = self.token_count(messages)
print(f"Input tokens: {token_num}")
response = await self.llm.achat(messages=messages)
self.context.response.answer = response.content.strip()
For details, refer to the Simple Op Guide, LLM Op Guide, and Advanced Op Guide (including Embedding, VectorStore, and concurrent execution).
📝 Step2 Configure Config
The following example demonstrates building an MCP (Model Context Protocol) service. Create a configuration file my_mcp_config.yaml:
backend: mcp
mcp:
transport: sse
host: "0.0.0.0"
port: 8001
flow:
demo_mcp_flow:
flow_content: MockSearchOp()
description: "Search results for a given query."
input_schema:
query:
type: string
description: "User query"
required: true
llm:
default:
backend: openai_compatible
model_name: qwen3-30b-a3b-instruct-2507
params:
temperature: 0.6
token_count: # Optional, configure token counting backend
model_name: Qwen/Qwen3-30B-A3B-Instruct-2507
backend: hf # Supports base, openai, hf, etc.
params:
use_mirror: true
🚀 Step3 Start MCP Service
flowllm \
config=my_mcp_config \
backend=mcp \ # Optional, overrides config
mcp.transport=sse \ # Optional, overrides config
mcp.port=8001 \ # Optional, overrides config
llm.default.model_name=qwen3-30b-a3b-thinking-2507 # Optional, overrides config
After the service starts, refer to the Client Guide to use the service and obtain the tool_call required by the model.
📚 Detailed Documentation
🚀 Getting Started
🔧 Op Development
- Op Introduction
- Simple Op Guide
- LLM Op Guide
- Advanced Op Guide
- Tool Op Guide
- File Tool Op Guide
- Vector Store Guide
🔀 Flow Orchestration
🌐 Service Usage
🤝 Contributing
Contributions of all forms are welcome! For participation methods, refer to the Contribution Guide.
📄 License
This project is licensed under the Apache 2.0 license.
Star 历史
GitHub • Documentation • PyPI