KFabric
KFabric est une plateforme Python-first de fabrication de corpus documentaires. Le projet vise un problème très concret : aider à construire un corpus traçable, pondéré et réutilisable à partir de sources hétérogènes, avant même de brancher un assistant RAG conversationnel.
Au lieu de passer directement du web au chat, KFabric se concentre d'abord sur la qualité du matériau documentaire :
- découverte de documents candidats
- collecte et normalisation
- scoring et décision documentaire
- récupération de fragments utiles dans des documents rejetés
- consolidation et synthèse
- préparation d'artefacts indexables pour des usages RAG futurs
Pourquoi KFabric
Dans beaucoup de pipelines RAG, la vraie faiblesse n'est pas le modèle mais le corpus. KFabric part de l'idée inverse :
- un bon corpus vaut mieux qu'une mauvaise conversation bien emballée
- les documents faibles contiennent parfois des signaux utiles à sauver
- la traçabilité et la prudence documentaire doivent exister dès le MVP
- un serveur MCP et une API REST doivent exposer exactement le même coeur métier
Ce que fait le MVP
Le MVP actuel couvre déjà un flux bout en bout :
- créer une requête documentaire
- découvrir des documents candidats
- collecter et parser un document
- attribuer un score global et des sous-scores
- accepter, rejeter, ou rejeter avec récupération partielle
- consolider les fragments sauvés
- générer une synthèse documentaire prudente
- construire un corpus final
- préparer un artefact d'indexation
Points forts
- API REST FastAPI pour piloter le pipeline corpus
- serveur MCP natif en Python
- workers Celery pour les traitements longs
- UI légère en Jinja2, HTMX et Alpine.js
- modèles SQLAlchemy 2 et migration Alembic initiale
- mode sécurisé activé par défaut
- approche corpus-first avant chat RAG complet
Architecture
Le projet est structuré comme un monolithe modulaire Python :
kfabric/api: routes REST, dépendances, sérialisationkfabric/mcp: tools, resources, prompts, serveur MCPkfabric/domain: contrats métier et enumskfabric/services: scoring, salvage, déduplication, synthèse, corpuskfabric/infra: base de données, observabilité, persistancekfabric/workers: tâches Celerykfabric/web: interface serveur renduemigrations: migration initialetests: tests API, MCP et logique métier
Stack technique
- Python 3.12
- FastAPI
- Pydantic v2
- SQLAlchemy 2 + Alembic
- Celery + Redis + RabbitMQ
- PostgreSQL prêt pour la production
- MCP Python SDK
- Jinja2 + HTMX + Alpine.js
Démarrage rapide
Installation minimale :
python3.12 -m venv .venv
source .venv/bin/activate
pip install setuptools wheel
pip install -e ".[dev]" --no-build-isolation
cp .env.example .env
uvicorn kfabric.api.app:app --reload
Si tu veux aussi les dépendances plus lourdes liées aux connecteurs et à la préparation RAG étendue :
pip install -e ".[dev,extended]" --no-build-isolation
L'application démarre ensuite sur :
- UI :
http://127.0.0.1:8000/ - API :
http://127.0.0.1:8000/docs
Démo produit
Deux scénarios de démonstration reproductibles sont fournis dans
docs/demo-scenarios.md.
Génération rapide :
export KFABRIC_DATABASE_URL="sqlite:////tmp/kfabric-demo.db"
export KFABRIC_STORAGE_PATH="/tmp/kfabric-demo-storage"
./.venv/bin/python scripts/generate_demo_scenarios.py \
--base-url "http://127.0.0.1:8010" \
--output /tmp/kfabric-demo-manifest.json
Les captures de démonstration peuvent ensuite être générées depuis l’UI locale, et les corpus sont exportables en HTML et en Markdown.
Aperçu visuel
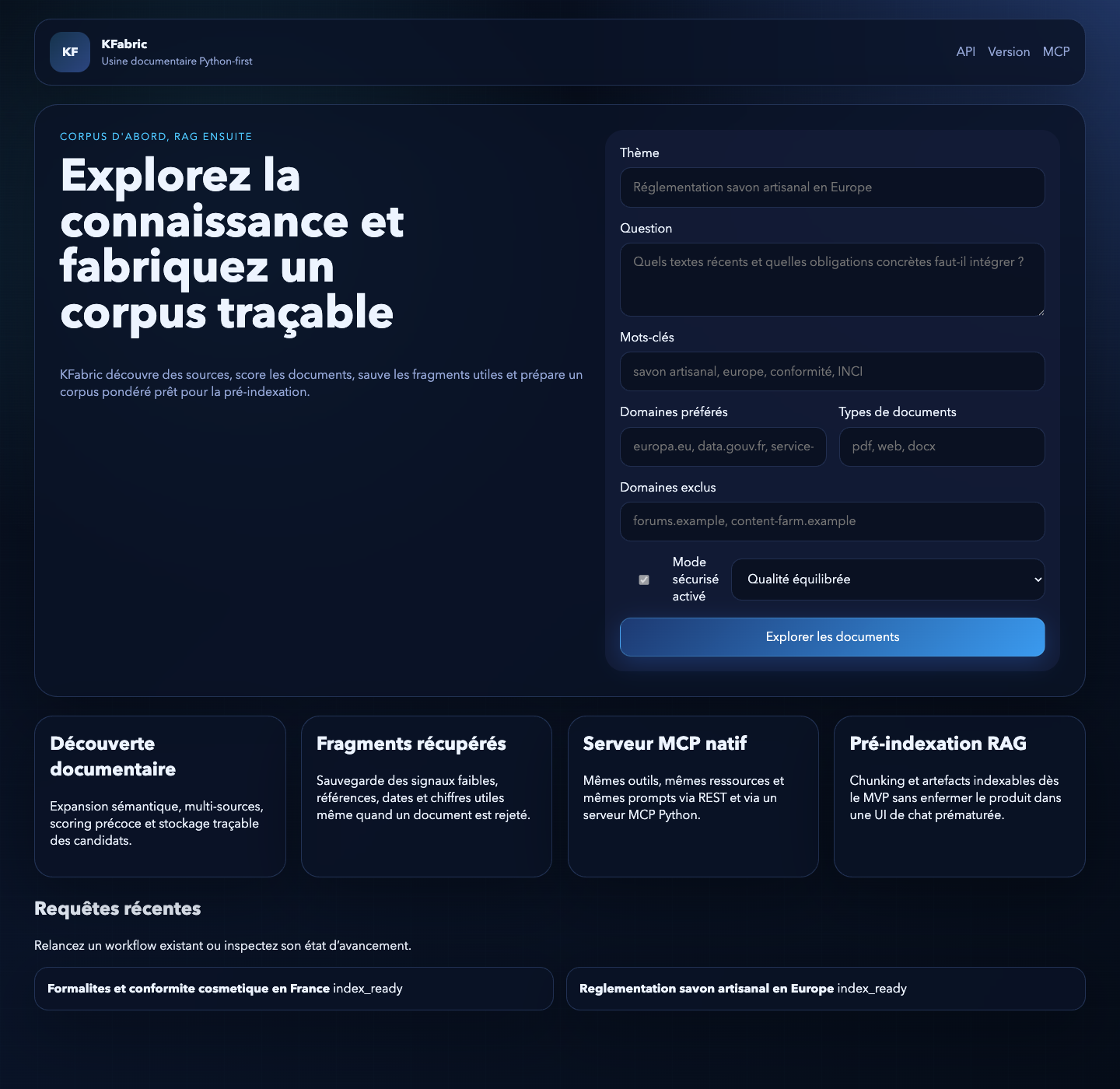
Page d'accueil avec les requêtes récentes :
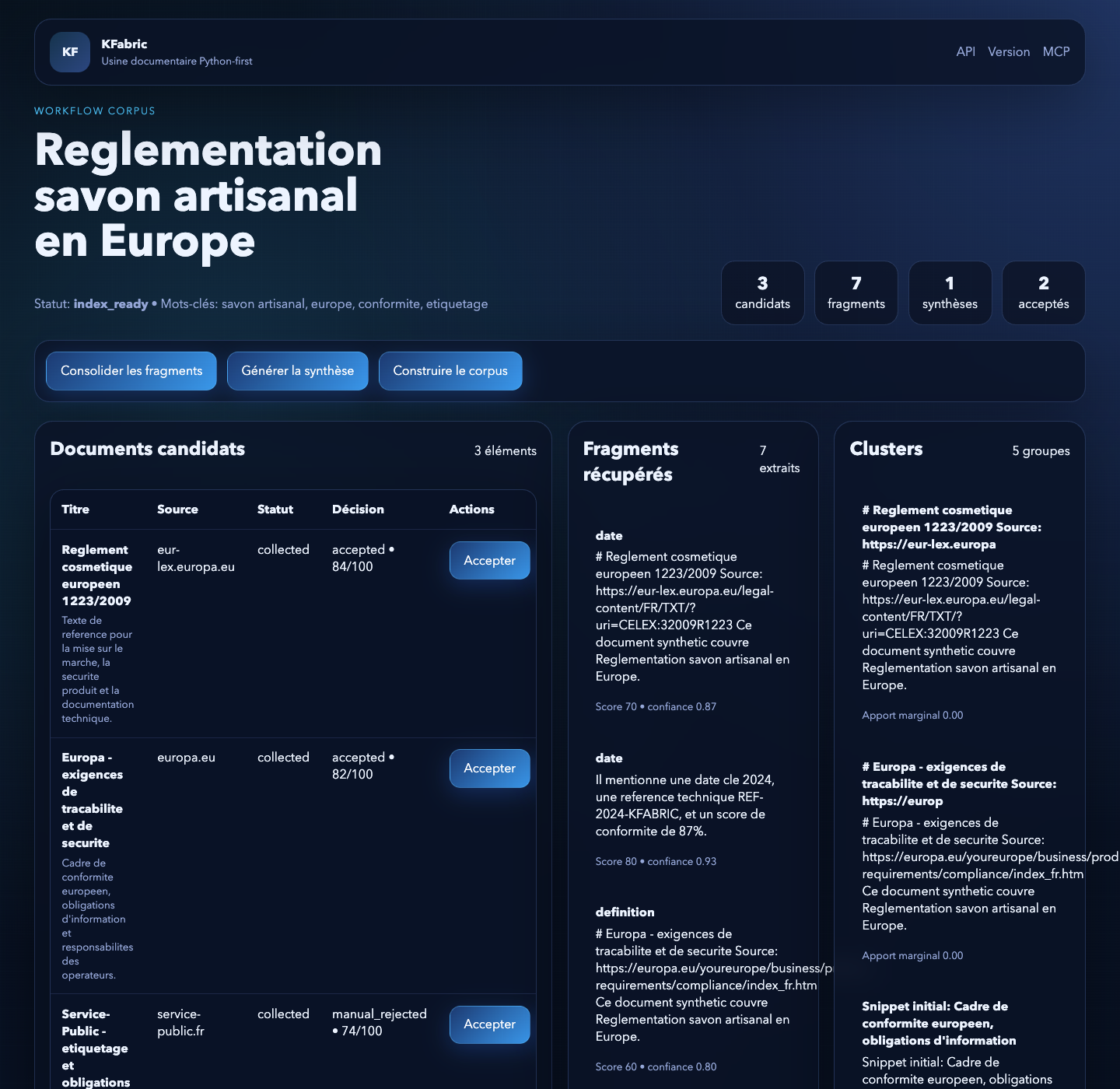
Workflow corpus-first sur le scénario "savon Europe" :
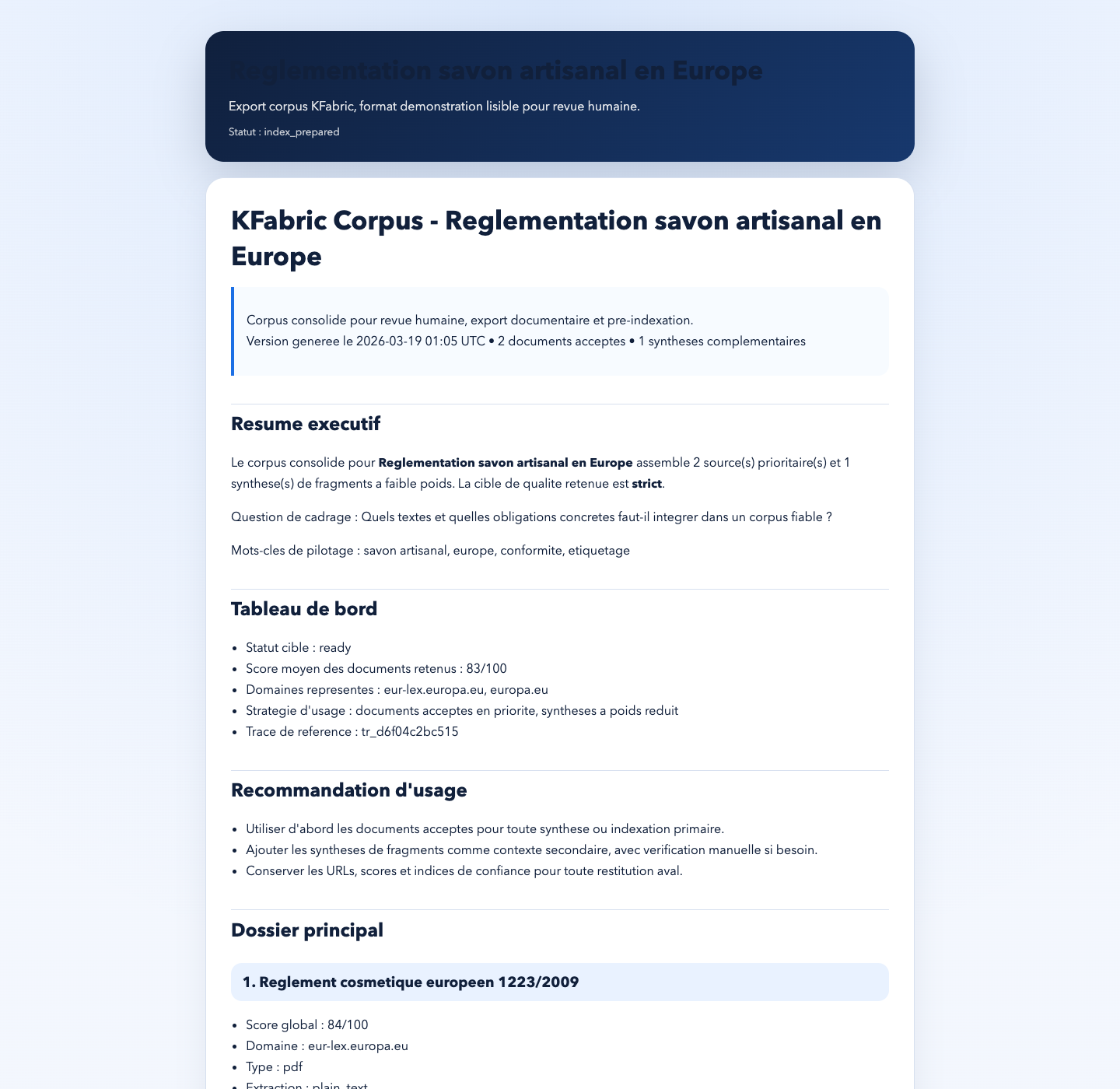
Export HTML prêt pour une démo ou une revue documentaire :
La galerie complète des scénarios validés est disponible dans
docs/demo-scenarios.md.
Vérification locale
Les tests principaux peuvent être lancés avec :
pytest
Le MVP a été vérifié localement avec :
- compilation Python
- tests API
- tests REST/MCP
- tests de scoring et de récupération de fragments
API et MCP
KFabric expose deux surfaces complémentaires :
- une API REST métier pour piloter tout le pipeline
- une API REST concordante MCP
- un serveur MCP natif en Python pour les tools, resources et prompts
Exemples de capacités exposées :
discover_documentslist_candidatesanalyze_documentaccept_documentreject_documentgenerate_fragment_synthesisget_corpus_status
Statut du projet
KFabric est aujourd'hui un MVP technique fonctionnel.
Ce qui existe :
- coeur métier corpus-first
- contrat REST principal
- socle MCP
- UI workflow
- migration initiale
- tests de base
Ce qui viendra ensuite :
- vrais connecteurs documentaires
- meilleure collecte multi-format
- embeddings réels et intégration vectorielle étendue
- scoring plus fin par domaine
- multi-tenant
- interface de production plus avancée
Développement avec assistance IA
Ce projet a été conçu et développé avec assistance IA, puis structuré, contrôlé, vérifié et arbitré manuellement.
L'IA a servi d'accélérateur pour :
- le prototypage
- l'implémentation initiale
- la documentation
- certaines itérations techniques
Les choix d'architecture, la validation du flux MVP et la cohérence produit ont été assumés et consolidés manuellement.
Licence
Licence non encore définie.