Vesta AI Explorer for macOS - macOS Tahoe 26
🌐 vesta-mac.pages.dev
Feb 11, 2026 --> Latest app release --> https://github.com/scouzi1966/vesta-mac-dist/releases/tag/v0.9.5
For the "Just take me to the download" people --> https://github.com/scouzi1966/vesta-mac-dist/releases/download/v0.9.5/Vesta-0.9.5.dmg
Install with brew --> brew install --cask scouzi1966/afm/vesta-mac
Vesta is a multi-backend AI chat application for macOS that runs models locally on Apple Silicon. It supports five AI backends simultaneously -- Apple Intelligence, MLX, llama.cpp, HuggingFace Inference API, and OpenAI-compatible API servers -- with runtime switching, vision understanding, text-to-speech, speech-to-text, image generation, video generation, and a full MCP server for programmatic control.
NOTE: SIDEKICK ONLY WORKS WITH LOCALLY INSTALLED CLAUDE CODE AT THE MOMENT. SUPPORT FOR OTHER MODELS AS MCP CLIENTS COMING SOON
Demo
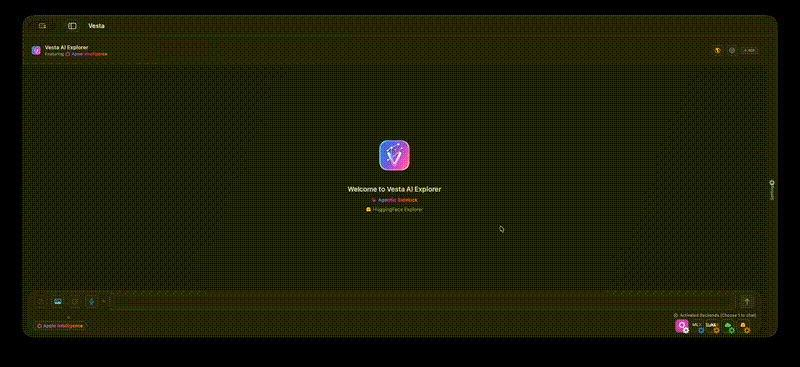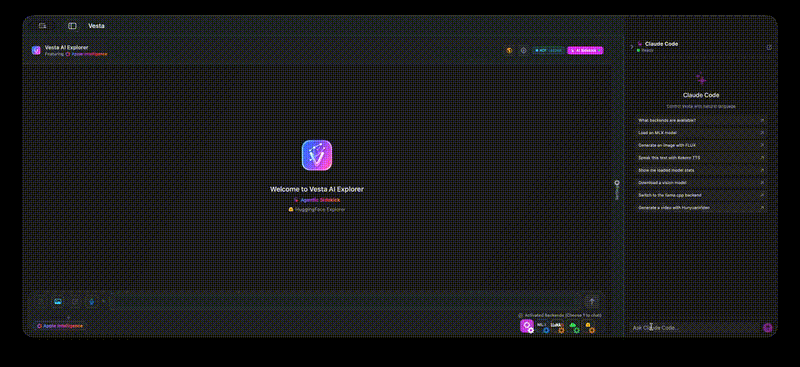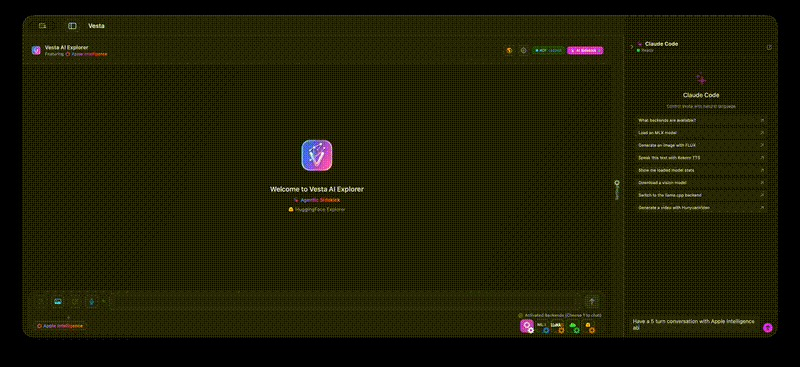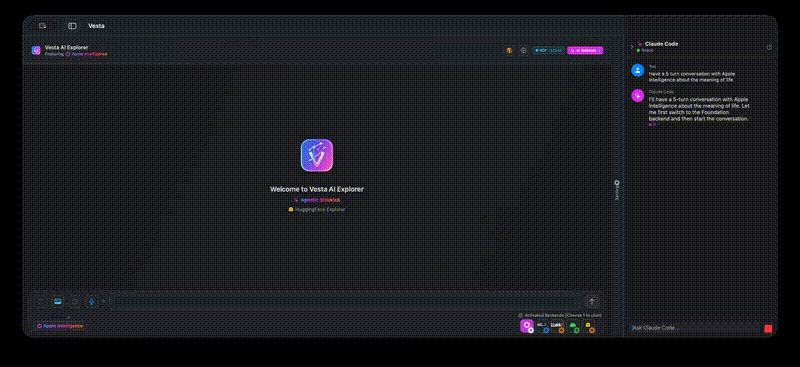
Click to watch the full demo video
Note that there is a known bug in Qwen3-VL models where it will loop indefinitely in some cases and never complete. In this case stop the generation and tweak your prompt. This is a model behavior, not the app. Reference: https://github.com/QwenLM/Qwen3-VL/issues/1611#issuecomment-3639175711
Vesta 0.9.5 (Feb 11, 2026)
94 commits, 2 months of development since v0.9.0
This is a major release that transforms Vesta from a two-backend chat app into a full multi-modal AI platform with five backends, MCP integration, and media generation capabilities. Explore the world of AI beyond ChatGPT!
🆕 New in 0.9.5
Multi-Backend Architecture
- HuggingFace Explorer -- Leverage the HuggingFace Pro subscription and inference providers partners for ImageGen, Videogen, Image edit, Whipser etc. I am not affiliated with HuggingFace but the pro sub is worth it.
- 5 simultaneous backends -- Apple Intelligence, MLX, llama.cpp, HuggingFace Explorer, and External AI (OpenAI-compatible) all active at once (Single chat routing)
- Runtime backend switching -- switch between backends without restarting the app
- Per-backend settings -- each backend has its own generation parameters, model selection, and configuration
- HuggingFace Browser -- Direct browse and download models from HuggingFace in-app
MCP Server (Model Context Protocol) - Agentic Sidekick!
- Full MCP server running on TCP loopback with token-based authentication
- Agentic Sidekick Vesta detects Claude Code when you enable MCP - Claude code acts as an agent with a NLI (Natural Language Interface) to the app. Ask Claude to set things up, have a conversation with any other model!
- 41+ tools -- backend management, chat, model download/load/unload, vision analysis, settings, conversation history search, diagnostics, UI navigation
- 6 resources -- app state, models, conversation, settings, logs, system info
- 7 prompts -- guides for Vesta, MLX, llama.cpp, HuggingFace, and common workflows
- AI Sidekick -- Claude Code integration for programmatic Vesta control
- Conversation history search -- full-text search and read-only SQL queries against the SQLite message database
HuggingFace Explorer (New Backend)
- Cloud inference via 16+ providers (Cerebras, Groq, Together, Fireworks, SambaNova, Nebius, Replicate, and more)
- Text-to-image generation -- FLUX.1 Schnell/Dev, FLUX.2, Stable Diffusion 3.x, SDXL with configurable size, guidance, and steps
- Image editing -- instruction-based editing with FLUX Kontext and FLUX.2 via Replicate
- Video generation -- Wan 2.2 T2V (text-to-video) with async polling
- Speech-to-text transcription -- OpenAI Whisper models via HuggingFace Inference API with 14 languages
- Vision/VLM -- Qwen2.5-VL, Qwen3-VL and other vision-language models via cloud
- Model browser -- search and discover models from HuggingFace Hub with download counts, likes, and gated model detection
- Reasoning display -- chain-of-thought rendering for models that emit
<think>tags (DeepSeek R1, QwQ, etc.) - 7-tab settings panel -- Chat, Vision, Image, Edit, Transcribe, Video, Settings
Text-to-Speech (TTS)
- Kokoro (82M) -- 46+ voices across 10+ languages, fast and high-quality
- Marvis (100M/250M) -- conversational TTS with voice cloning support via reference audio
- Models download on first use from HuggingFace
Speech-to-Text (STT) -- WhisperKit
- On-device transcription via WhisperKit CoreML -- zero network required
- 6 model sizes -- Tiny (39M) through Large V3 (1.5B) and Large V3 Turbo (809M)
- 28+ languages with auto-detect
- Per-segment timing and speed ratio reporting
Jinja Template Support (minja)
- Full Jinja2 template parsing for GGUF models via llama.cpp's minja library
- Correctly renders chat templates embedded in model metadata
- Falls back to llama_chat_apply_template() for non-Jinja templates
GGUF Model Browser
- Search and browse GGUF models from HuggingFace Hub
- Capability badges: Vision, Tool Use, Reasoning, Coding, Math, Multilingual
- Split/multipart file detection
- Automatic mmproj detection for vision models
MLX Improvements
- Qwen3-VL M-RoPE patch -- +81% performance improvement for vision inference (auto-applied via script)
- KV cache controls exposed -- max KV size, quantization bits, prefill step size
- MLX benchmark tool (mlx-bench) for standalone performance testing
- Wired memory set to 90% of GPU recommended working set for large model performance
🔧 Improvements
- Per-message metrics -- token count and tokens/sec stored with each message in the database
- Green parameter labels -- visual indicator when a generation parameter matches the model's configured default
- Binary voice format -- Kokoro voice files converted from JSON to binary (144 MB down to 27 MB)
- Conversation history view with backend filtering and pagination
- One-command build --
build-from-scratch.shhandles submodules, patching, llama.cpp library build, and Xcode build - Distribution pipeline -- automated DMG creation, notarization, and GitHub release via
build-vesta-mac-dist.sh - Automated testing framework -- 44+ UI tests via MCP-based test runner
🐛 Bug Fixes
- Fix AVKit VideoPlayer crash during SwiftUI transitions (disabled transition animations)
- Fix download progress stuck at 0% and crash in llama.cpp streaming
- Fix TTS mode hijacking text generation when both TTS and LLM models are loaded
- Fix O(N^2) reasoning parser performance
- Fix reasoning parser stripMarkers bug and chat history contamination
- Fix streaming throttle not kicking in when content scrolls off-screen
- Fix llama.cpp default context size (2048 changed to 16384 for Qwen3-VL)
- Fix Continuity Camera Swift 6 concurrency crash in Release builds (Objective-C workaround)
- Fix NSHostingView constraint crash in MLX settings window (non-observing wrapper)
- Fix MoE warmup crash for models with 32+ experts (reduced warmup batch size)
- Fix mxfp4 MoE Metal shader crash (skip warmup for mxfp4 models)
- Fix ESpeakNG unsealed contents causing notarization failure
- Fix GGUF vision model image handling and model deduplication
Vesta 0.9.0 (Dec 10, 2025)
🆕 New in 0.9.0
- Vision capabilities with Qwen3-VL model (describe images, analyze screenshots)
- Continuity Camera input (capture photos directly from iPhone/iPad)
- Code syntax highlighting for 20+ programming languages
- Edit responses inline after generation
- HTML preview for rendered content
- Enhanced LaTeX math rendering in blockquotes
- Improved rendering engine with real-time code block highlighting
Features
- Apple Intelligence -- on-device AI via Foundation Models framework (always available)
- MLX Backend -- Apple Silicon optimized inference with mlx-swift (Qwen3-VL vision models)
- llama.cpp Backend -- GGUF model support with full Metal GPU acceleration and Jinja templates
- HuggingFace Explorer -- cloud inference, image/video generation, transcription via 16+ providers
- External AI -- connect to any OpenAI-compatible API server (LM Studio, Ollama, etc.)
- Vision -- image understanding via Qwen3-VL (MLX, llama.cpp, or HuggingFace)
- Text-to-Speech -- Kokoro, Marvis (with voice cloning), and Orpheus TTS engines
- Speech-to-Text -- WhisperKit on-device transcription (Tiny through Large V3)
- MCP Server -- 41+ tools for programmatic control, model management, and AI Sidekick integration
- GitHub Flavored Markdown -- tables, task lists, strikethrough via remark/rehype pipeline
- LaTeX Math -- inline and block math rendering with KaTeX
- Code Highlighting -- 20+ languages with real-time streaming highlight
- Liquid Glass UI -- native macOS Tahoe design
- App Sandbox -- Developer ID signed and Apple notarized
📋 Installation
- Download the DMG from the latest release
- Open the DMG and drag Vesta to Applications
- Launch Vesta from Applications
- First Run: right-click and select "Open" if prompted by Gatekeeper
📱 Requirements
- macOS 26.0 (Tahoe) or later
- Apple Silicon Mac (M1/M2/M3/M4)
- Microphone access for voice input and STT
- Internet access for HuggingFace backend and model downloads (on-device backends work offline after model download)
🔒 Security & Privacy
- Signed with Developer ID Application: Soprano Technologies Inc.
- Notarized by Apple
- App Sandbox enabled
- On-device backends (Apple Intelligence, MLX, llama.cpp) process everything locally -- no data sent to servers
- HuggingFace and External AI backends require network access for inference
- API tokens stored in macOS Keychain
🔗 Related
- Source Code: https://github.com/scouzi1966/vesta-mac
- Distribution: https://github.com/scouzi1966/vesta-mac-dist (this repo)
- CLI Alternative: https://github.com/scouzi1966/maclocal-api
💬 Support
📄 License
(c) 2025-2026 Soprano Technologies Inc. All rights reserved.
🏗 Built With
- Apple Intelligence -- Foundation Models framework
- MLX -- mlx-swift + mlx-swift-lm for Apple Silicon inference
- llama.cpp -- GGUF inference with Metal acceleration
- WhisperKit -- CoreML-based Whisper speech-to-text
- mlx-audio -- Kokoro/Marvis/Orpheus TTS
- SwiftUI -- native macOS interface
- KaTeX -- math rendering
- highlight.js -- code syntax highlighting
- remark/rehype -- markdown processing pipeline
Built with automated distribution pipeline | Notarized and code-signed | Apple Silicon native